Was macht TaxLetterAI genau?
Die Anwendung liest Steuerbescheide oder Steuererklärungen – Copy-Paste oder PDF mit OCR – plus 3 bis 6 Stichpunkte Ihres Teams ein und gibt sofort einen fertigen Mandantenbrief aus. Fokus: Steuerberater:innen sparen Zeit, bleiben fachlich sauber und liefern Texte, die Mandanten verstehen.
- Klar formulierte, ausführliche Mandanten-Erklärung.
- Sauber strukturiert nach Ergebnis, Gründen, Auswirkungen, Hinweisen.
- Verständlich statt technischer Formulierungen.
- Sofort in Word einfügbar, ohne Formatierungsarbeit.
- Auf Wunsch inklusive automatischer Extraktion von Erstattung/Nachzahlung, Fristen und Besonderheiten.
Input & Output auf einen Blick
Sie wählen, ob der Originalbescheid oder die Steuererklärung als Basis dient. TaxLetterAI kombiniert beides mit Ihren Stichpunkten und liefert eine fertig aufbereitete Erklärung.
Originalbescheid als Scan oder Copy-Paste inklusive kurzer Stichpunkte der Mitarbeiterin.
Die Steuererklärung als PDF oder Text (z. B. DATEV-Export) – genauso verarbeitet wie ein Bescheid.
Detaillierte Mandanten-Erklärung mit Zusammenfassung der Zahlen, Fristen, Erstattungen/Nachzahlungen und Handlungsempfehlungen.
Arbeitsablauf in drei Schritten
- Eingabe: Bescheid/Erklärung hochladen oder Text einfügen, Stichpunkte ergänzen, optional Zahlenfelder befüllen.
- Analyse: AI liest OCR-Daten aus, mischt Stichpunkte ein, strukturiert das Ergebnis und markiert Fristen sowie Beträge.
- Output: Word-ready Text für Copy-Paste oder PDF-Export – alles bleibt im Browser.
UI & Demo-Brief (Demodaten)
Echter Screenshot: Oben sehen Sie die Eingabeoberfläche (Mandantenfelder, Upload, Stichpunkte), darunter das daraus erzeugte Anschreiben.
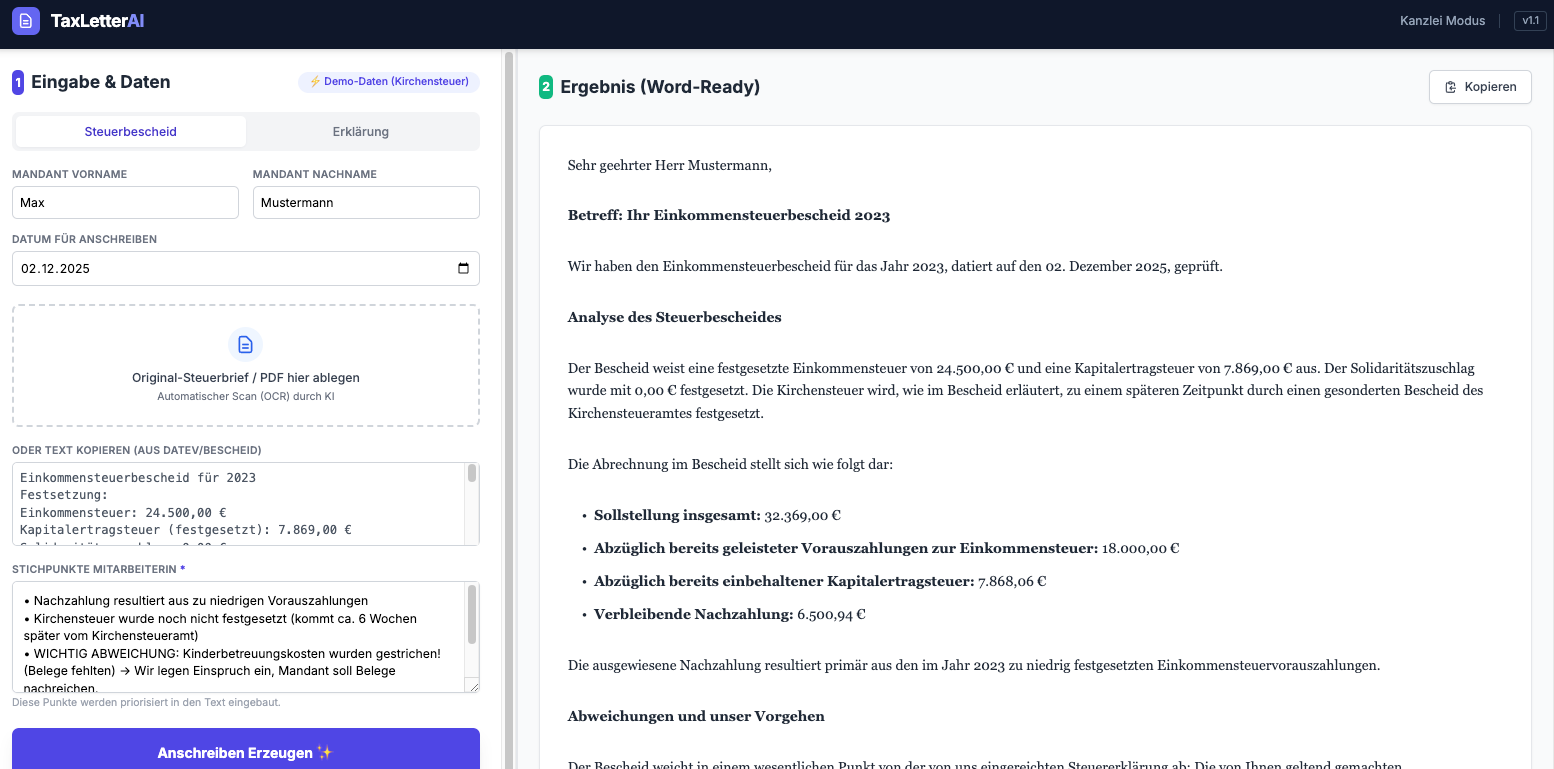

Was Mandanten erhalten
- Ausführliche Mandanten-Erklärung mit sauberer Struktur und verständlicher Sprache.
- Zusammenfassung der wichtigsten Zahlen, Fristen und To-Dos direkt im Text.
- Word-ready Ausgabe zum direkten Copy-Paste – ohne Nachformatierung.
- Block „Was bedeutet das für Sie?“ mit klaren Handlungsempfehlungen.
FAQ – Verarbeitung & Datenschutz beim Bescheid-Erklärungs-Tool (aktuelle Architektur)
1. Wird das PDF selbst gespeichert?
Nein.
Das PDF wird nicht dauerhaft gespeichert. Es bleibt kurzzeitig im Browser-Speicher und wird anschließend zur Texterkennung an Google gesendet.
2. Was passiert technisch mit dem PDF beim Hochladen?
Das PDF wird:
- im Browser-Speicher gehalten
- an Google Gemini Vision (OCR) übermittelt
- dort verarbeitet
- danach verworfen
- im Browser gelöscht, sobald die Seite verlassen oder neu geladen wird
3. Werden die aus dem PDF extrahierten Textdaten gespeichert?
Nein.
Der extrahierte Text wird ausschließlich zur Erstellung des Mandantenbriefs genutzt und nur temporär im Browser gehalten.
4. Können PDF oder Textdaten im Systemlog des Anbieters auftauchen?
Ja.
Sowohl PDF-Inhalte (base64) als auch extrahierte Texte können als Teil des technischen Requests für maximal 30 Tage im internen Sicherheitslog des AI-Anbieters stehen.
Das basiert auf den Standardbedingungen der Google-API.
5. Wer hat Zugriff auf diese Sicherheitslogs?
Nur ein sehr kleiner, speziell autorisierter Sicherheitskreis beim Anbieter – ausschließlich im Fall eines Sicherheits- oder Missbrauchsereignisses.
Keine Entwickler, kein Support, kein Produktteam.
6. Wofür existieren diese Sicherheitslogs?
Für:
- Missbrauchserkennung
- Angriffsabwehr
- technische Störungsanalyse
- Erfüllung gesetzlicher Prüfpflichten
Nicht für Training oder Produktverbesserung.
7. Was passiert nach den 30 Tagen?
Alle Log-Daten (PDF und extrahierter Text) werden nach spätestens 30 Tagen automatisch gelöscht.
Es bleibt keine Kopie bestehen.
8. Fließen PDF oder Textdaten in das Modelltraining ein?
Nein.
Laut Anbieterbedingungen werden API-Daten nicht für Training oder Weiterentwicklung der Modelle verwendet.
9. Welche Daten werden überhaupt übermittelt?
Übermittelt werden:
- das PDF für die Dauer der OCR-Verarbeitung
- der daraus extrahierte Text
- die eingegebenen Fachangaben
- der vollständige Prompt (ggf. inkl. personenbezogener Details)
Diese Daten werden durch die Anwendung selbst nicht gespeichert.
10. Welches Sicherheitsniveau hat die Verarbeitung?
Die Verarbeitung folgt Sicherheitsstandards, wie sie auch Banken, Versicherer und große Konzerne nutzen.
Der 30-Tage-Sicherheitsbereich ist stark abgeschirmt und nur einem minimalen autorisierten Sicherheitskreis zugänglich.
11. Warum muss der fertige Text manuell gespeichert werden?
Der erzeugte Mandantenbrief wird bewusst nicht automatisch gespeichert. Dadurch:
- bleiben alle Mandantendaten vollständig in der Kanzlei
- entstehen keine Kopien in großen externen IT-Infrastrukturen (z. B. Rechenzentren von Google, Microsoft oder ähnlichen Anbietern)
- behält die Kanzlei die volle Kontrolle über Speicherung, Ablage und Löschung
Der manuelle Schritt (Word öffnen → Text einfügen → lokal/Netzlaufwerk speichern) ist ein wichtiges Datenschutzmerkmal.
12. Wo läuft die Browser-Anwendung technisch gesehen?
Die Benutzeroberfläche liegt auf der Google Cloud Platform.
Für den Anwender ist das unerheblich, weil:
- die Oberfläche beim Öffnen vollständig in den Browser geladen wird
- die Bedienung lokal im Browser erfolgt
- die AI-Verarbeitung (OCR + Textgenerierung) durch Google ausgeführt wird
- im Hosting-System selbst keine Mandantendaten gespeichert werden
Empfohlene Maßnahmen für Kanzleien (Produktivbetrieb)
13. Eigener API-Schlüssel und Pseudonymisierung
Für produktiven Kanzlei-Einsatz empfiehlt sich:
- Nutzung eines eigenen Google-Gemini-API-Schlüssels
- Pseudonymisierung von Mandantendaten während der Verarbeitung (z. B. „{Mandant}“ statt Klarname)
- Einsetzen der echten Angaben erst im finalen Word-Dokument
So werden personenbezogene Daten auf ein Minimum reduziert.
14. Erweiterte Sicherheitsoptionen (Enterprise-Stufen, optional)
Für besonders strenge Anforderungen gibt es weitere Optionen:
- Enterprise-Tier mit reduziertem Logging
- Private / isolierte Gemini-Ausführung für maximale Sicherheit (wird u. a. von Banken, Versicherern und Behörden genutzt)
- Regionale Datenkontrolle innerhalb der EU
Diese sind optional, bieten aber zusätzliche Sicherheitsstufen.
15. Betrieb mit eigenem API-Schlüssel der Kanzlei
Die Anwendung kann so betrieben werden, dass die Kanzlei ihren eigenen Google-API-Schlüssel hinterlegt.
In diesem Fall:
- läuft die Anwendung weiterhin im Browser der Kanzlei
- die gesamte AI-Verarbeitung erfolgt über den eigenen API-Zugang
- der Schlüssel wird nicht gespeichert, sondern nur temporär im Browser genutzt
- der Schlüssel wird nicht an unsere Systeme übertragen
- die Kanzlei kontrolliert Sicherheit, Region, Logging und Abrechnung selbst
Für viele Kanzleien ist das die bevorzugte Betriebsart, da die technische Verantwortung vollständig bei der Kanzlei liegt.
16. Wer trägt die datenschutzrechtliche Verantwortung, wenn die Kanzlei ihren eigenen API-Schlüssel nutzt?
Wenn die Kanzlei ihren eigenen Google-Gemini-API-Schlüssel einsetzt, liegt die gesamte datenschutzrechtliche Verantwortung bei der Kanzlei selbst.
In diesem Fall:
- verarbeitet die Anwendung keinerlei Daten selbst
- erfolgt die komplette AI-Verarbeitung ausschließlich über den eigenen Zugang der Kanzlei
- besteht kein Zugriff durch uns und keine Einsicht in Inhalte, PDFs oder Ergebnisse
- ist die Kanzlei selbst Vertragspartner von Google und damit auch für Datenschutz, Logging, Regionseinstellungen und Löschung zuständig
Die Anwendung stellt in diesem Szenario lediglich die Oberfläche bereit.
Alle relevanten Datenflüsse und Entscheidungen liegen vollständig unter Kontrolle der Kanzlei.